

El principal peligro de la IA podría ser otro
Paro masivo, obsolescencia del ser humano, discriminación de minorías… Peligros normalmente asociados al desarrollo de la Inteligencia Artificial (IA) palidecen al lado de lo que supondría modelar nuestros pensamientos con perfecto detalle.
Ninguno de nosotros capta la realidad del mundo que nos rodea “tal cual es”, de manera objetiva y completa. En su lugar, contamos con un complejo sistema nervioso y un cuerpo imperfecto, pero repleto de sensores, que nos permite capturar información procedente de nuestro entorno y elaborar una respuesta física y/o mental acorde a nuestras necesidades y a la exigencias impuestas por dicho entorno. Este proceso, que tiene lugar de manera continua e ininterrumpida a lo largo de toda nuestra vida, se le conoce grosso modo como “percepción”, y juega un papel clave en nuestro aprendizaje, nuestra conducta y hábitos, así como en nuestras relaciones con los demás. No debe sorprendernos entonces que gobiernos y empresas de todo el mundo estén realizando una fuerte apuesta por desarrollar tecnologías capaces de modelar nuestra percepción acerca del contenido online que consumimos – en promedio cada persona pasaba alrededor de 7 horas diarias conectada a Internet en 2022 – con el fin último de influir en nosotros de maneras tan sutiles e imperceptibles que no seamos siquiera conscientes de su influjo.
En primer lugar, sentemos las bases de qué entendemos por percepción. Esta palabra tiene su origen en el latín «perceptio», que a su vez deriva del verbo «percipere», compuesto por el prefijo «per-» (que denota completitud o intensidad) y el verbo «capere» (que significa «capturar» o «agarrar»). Por lo tanto, etimológicamente, «percepción» se refiere a la acción de capturar o agarrar completamente algo a través de los sentidos. Así, por percepción nos referimos al proceso de captación, interpretación y organización de la información sensorial que recibimos a través de nuestros sentidos (vista, oído, tacto, olfato y gusto). Es a través de nuestra percepción que construimos una representación interna de la nuestro entorno.
Nuestra percepción se ve influida por diversos factores, incluyendo nuestras experiencias pasadas, nuestros conocimientos previos, nuestras creencias y nuestras expectativas. Estos factores pueden filtrar, seleccionar y dar forma a la forma en que percibimos la información sensorial. Por ejemplo, si hemos tenido experiencias negativas con perros en el pasado, es posible que percibamos a un perro en la calle como amenazante, aunque en realidad no represente ningún peligro. Además, nuestra percepción puede ser susceptible a ilusiones y sesgos cognitivos, lo que puede llevarnos a interpretar erróneamente la información sensorial.
Estos sesgos cognitivos, interiorizados en nuestros cerebros mediante un largo proceso de evolución durante miles de años, simplifican la gran cantidad de estímulos externos a los que estamos expuestos en nuestro día a día, permitiendo a nuestro cerebro enfocarse en decisiones que consideramos prioritarias. Muchos de estos sesgos cumplen un propósito claro desde una perspectiva darwiniana, y constituyeron una herramienta esencial cuando los seres humanos se organizaban en sociedades de tipo familiar o tribal, pequeñas y fuertemente jerarquizadas. Sin embargo, en el mundo contemporáneo, especialmente en sociedades como la nuestra, altamente digitalizadas, los beneficios asociados a estas respuestas casi instintivas son menos evidentes.
Por ejemplo, alguien que tenga una opinión política arraigada tenderá a buscar información que respalde sus puntos de vista y a descartar o minimizar evidencia que los contradiga. Este sesgo puede limitar nuestra capacidad de considerar diferentes perspectivas y dificultar el cambio de opinión basado en evidencias contrarias, algo peligroso en una democracia. A estas alturas, no es noticia que esto es precisamente lo que ocurre cuando usamos redes sociales como Facebook o Twitter, donde las “burbujas de polarización”, también conocidas como “cámaras de eco”, son ya una realidad aceptada.
Igualmente, si vemos noticias frecuentes sobre robos en nuestra ciudad, es más probable que sobreestimemos la frecuencia de los robos en comparación con otros delitos menos destacados en los medios, distorsionando de este modo nuestra percepción de los riesgos y dirigiéndonos hacia decisiones basadas en eventos destacados pero poco representativos de la situación real.
Hasta ahora, esta clase de sesgos cognitivos eran aprovechados en tanto en cuanto las personas responsables de producir contenido online fueran hábiles en el manejo de las herramientas de comunicación, pero siempre estaban limitadas por basarse en un conocimiento intuitivo del proceso. Con la IA, esto está pasando a ser un conocimiento estimado a priori, susceptible de ser medido y usado para anticipar la respuesta del público a un determinado estímulo, optimizando su impacto en el momento del lanzamiento.
La IA no es únicamente un conjunto de técnicas orientadas a imitar aspectos de la cognición humana, sino que nace de un deseo de comprender mejor nuestra propia psicología. Cuando entrenamos sistemas de IA en bases de datos que tienen que ver con nuestra reacción a determinados estímulos, en definitiva estamos obteniendo modelos computacionales que reflejan de manera fiel cómo respondemos en general los humanos a ese aspecto concreto de la percepción. Empresas como la americana Memorable se han especializado en ello. En su caso, emplearon bases de datos que relacionaban vídeos cortos con la probabilidad de que diferentes personas recordaran haber visto esos vídeos tras un cierto intervalo de tiempo, obteniendo así un modelo capaz de estimar la memorabilidad de imágenes como las típicamente empleadas en campañas publicitarias. Y lo que es más importante, de aconsejar a sus clientes acerca de cómo hacer aún más memorables sus campañas de marketing. Cuando esta tecnología alcance la madurez, podríamos estar hablando de la absoluta imposibilidad – en términos físicos – de olvidar el anuncio promocionando el coche de moda.
Y éste no es el único ejemplo. Existen herramientas similares para predecir cómo de bonita nos parecerá una fotografía, qué clase de emociones experimentaremos ante una pintura, a qué partes de una imagen prestamos atención… De hecho, todo el concepto del neuromarketing pivota hoy en día alrededor de este tipo de sistemas computacionales.
Por otro lado, medios de todo el mundo se han hecho eco a estas alturas de la carta abierta que una serie de personalidades del ámbito cultural, como el divulgador e historiador israelí Yuval Noah Harari, firmaron apoyando que se detuviera el entrenamiento de modelos como el chatbot ChatGPT. Añadiendo más leña al fuego, uno de los mayores impulsores y defensores de la IA, y de los sistemas basados en redes neuronales artificiales, Geoffrey Hinton, renunciaba a su puesto en Google para criticar abiertamente el rumbo tomado por ciertos actores en la carrera hacia IAs más potentes, sin atender a las posibles consecuencias que podrían tener para el resto de la sociedad. Estas declaraciones de Hinton, ganador del máximo galardón dentro del ámbito de las ciencias de la computación y apodado como “padrino de la IA” por sus contribuciones al campo, han sido usadas como arma arrojadiza por muchos medios deseosos de alimentar la idea de que estamos ante un nuevo tipo de inteligencia, una con el potencial de dejarnos a todos sin empleo o incluso de aniquilar a toda nuestra especie. Sin embargo, las palabras de Hinton se parecen más a las de aquellas voces que se alzaron en 2020, cuando se estrenó en Netflix el documental “The Social Dilemma” (si no lo ha visto ya, se lo recomiendo encarecidamente). En él, se exponen algunas de las estrategias implementadas por gigantes tecnológicos como Facebook o Google para incrementar el tiempo que pasamos en sus redes sociales y servicios online, siempre con fines comerciales que nada tienen que ver con el bienestar del usuario.
En conclusión, es evidente que vivimos una década en la cual la IA avanza a un ritmo vertiginoso, a menudo más rápido de lo que somos capaces de anticipar ni siquiera los especialistas en la materia. Esto es precoupante, especialmente considerando el uso intensivo que casi todas las empresas están haciendo de estos sistemas inteligentes y que nos fuerza a todos a usarlos, con el consiguiente impacto que puede llegar a tener esta tecnología en absolutamente todos los campos de nuestra vida. Sin embargo, en última instancia la problemática expresada aquí no es sino un aviso acerca de la espada de Damocles que pende sobre nuestra capacidad para tomar decisiones libres. ¿Aceptaremos el desafío de buscar soluciones antes de que sea demasiado tarde?
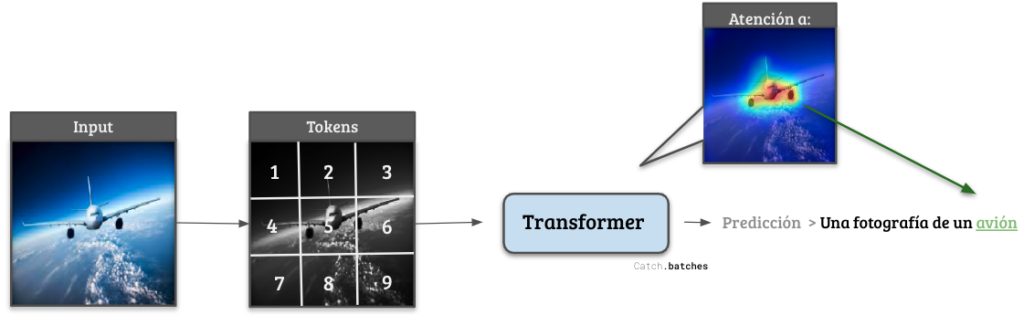
Figura 1: Diagrama de cómo funciona un sistema de clasificación de imágenes basado en Transformers. Su gran ventaja radica en la capacidad de ser selectivo con diferentes regiones de los datos de entrada.
En diciembre de ese mismo año, el mismo equipo de investigadores publicó otro artículo llamado “Atención es todo lo que necesitas”, que en menos de 5 años acumula más de 68.000 citas[4]. En él, los autores introdujeron una clase novedosa de neuronas artificiales, las cuales bautizaron como Transformers. La característica más reseñable de este tipo de neuronas es capacidad de prestar atención a zonas específicas del input, permitiéndoles enfocar su procesamiento únicamente en las partes del texto, la imagen o el audio más relevantes para el éxito de la tarea, como se aprecia para un ejemplo en la Figura 1. Son estos Transformer, junto con la codificación de textos e imágenes mediante tokens, los actuales pilares que soportan toda una nueva generación de modelos de IA: Chat-GPT, DALL-E2[5], Whisper[6]… Y ahora, GPT-4.
Según lo indicado por OpenAI, esta versión del potente modelo de lenguaje sería capaz de procesar desde fotos realistas hasta diagramas y esquemas de la misma manera que procesa un texto normal, algo inaudito hasta ahora. La compañía no ha comunicado ningún aspecto técnico, marcando así un punto de inflexión con respecto a la mentalidad de código libre o abierto imperante entre la comunidad tecnológica. Desde su fundación, corporaciones como Google, Facebook o Amazon apostaron por potentes equipos de investigación procedentes de las mejores universidades del mundo para desarrollar nuevas vías de negocio. Como aliciente para estos profesionales, sus ideas eran luego publicadas en forma de artículos científicos. Esta estrategia les permitió posicionarse como una cara amable con el usuario, permitiendo señalar aspectos a mejorar, o desarrollar sus propias herramientas a partir de dicho código abierto, aceptando el riesgo de que sus competidores usaran luego los frutos de su trabajo gratis.
Y es que en efecto, OpenAI, empresa cofundada por Elon Musk en 2015, no ha dudado en aprovechar al máximo las ideas presentadas en los artículos que comentábamos antes para convertirse en un auténtico gigante y posicionarse como una empresa líder en el sector. De hecho, se amparan en la feroz competencia existente en el mercado o en posibles malos usos para explicar su silencio a nivel técnico. Han llegado incluso a afirmar que “[Google] se equivoca […]. Si crees que la IA va a ser extremada e increíblemente potente, y que puede emplearse con malos fines, entonces no tiene sentido que sea de acceso abierto. Es una mala idea…” en palabras de un ex-empleado de Google ahora en OpenAI. En última instancia, puede que la estrategia de código abierto de Google haya sido “demasiado” idealista, y que el futuro de la IA haya comenzado a tener un dueño.
Las implicaciones que tendrá este cambio de estrategia comercial no son evidentes todavía. ¿Comenzarán otras compañías a proteger celosamente su propiedad intelectual? Es indudable que gran parte del éxito y rápida adopción de herramientas basadas en IA se debe a la política de código abierto auspiciada hasta ahora por estas empresas. Sencillamente, cualquier individuo con unos conocimientos básicos de programación podía probar en cuestión de minutos sus propias ideas utilizando para ello la tecnología más avanzada. Si las IAs se convierten en otro producto SaaS (Software-As-A-Service) cuyas especificaciones queden fuertemente blindadas y en secreto, es posible que estemos condenados a que sólo los agentes con mayor capacidad financiera puedan tener acceso al desarrollo de tecnología avanzada. Y eso, en un mundo cada vez más controlado y monitorizado por algoritmos inteligentes, es algo que debiera preocuparnos.
Referencias
[1]: OpenAI, 2023. GPT-4 Technical Report. https://doi.org/10.48550/arXiv.2303.08774
[2]: Man, K., Kaplan, J.T., Damasio, A., Meyer, K., 2012. Sight and Sound Converge to Form Modality-Invariant Representations in Temporoparietal Cortex. J. Neurosci. 32, 16629–16636. https://doi.org/10.1523/JNEUROSCI.2342-12.2012
[3]: Kaiser, L., Gomez, A.N., Shazeer, N., Vaswani, A., Parmar, N., Jones, L., Uszkoreit, J., 2017. One Model To Learn Them All. https://doi.org/10.1007/s11263-015-0816-y
[4]: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention Is All You Need. Advances in Neural Information Processing Systems 2017-December, 5999–6009. https://doi.org/10.48550/arxiv.1706.03762
[5]: Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M., 2022. Hierarchical Text-Conditional Image Generation with CLIP Latents. https://doi.org/10.48550/arxiv.2204.06125
[6]: Radford, A., Kim, J.W., Xu, T., Brockman, G., McLeavey, C., Sutskever, I., 2022. Robust Speech Recognition via Large-Scale Weak Supervision. https://doi.org/10.48550/arXiv.2212.04356